В 2026 году мощное железо позволяет превратить домашний компьютер в полноценную станцию искусственного интеллекта. Больше не нужно переживать за утечку данных в облако или платить за ежемесячные подписки. В этой статье мы разберем, как поднять локальную языковую модель (LLM) и заставить её работать на благо вашей продуктивности.
Почему локальный ИИ — это стандарт 2026 года?
-
Конфиденциальность: Ваши запросы, пароли и куски рабочего кода никогда не покинут пределы вашего ПК.
-
Скорость и доступность: Модели работают без интернета и задержек, связанных с загрузкой серверов.
-
Гибкость: Вы сами выбираете «мозги» для своего ИИ — от специализированных кодеров до творческих моделей.
Что понадобится для запуска?
Для комфортной работы моделей уровня Llama 3 (8B) или Mistral критически важен объем видеопамяти (VRAM).
-
Минимум: 8 ГБ VRAM (запуск с квантованием).
-
Оптимально: 16–24 ГБ VRAM (например, карты 40-й или 50-й серии RTX). Это позволит запускать модели практически мгновенно.
Шаг 1: Выбор «движка» (Ollama vs LM Studio)
Для Windows сейчас есть два фаворита:
-
Ollama: Работает как служба в фоне. Идеально подходит, если вы хотите интегрировать ИИ в другие приложения или терминал.
-
LM Studio: Имеет красивый графический интерфейс. Позволяет искать и скачивать модели прямо внутри программы (использует базу Hugging Face).
Шаг 2: Выбор и загрузка модели
В 2026 году мир LLM огромен. Что качать?
-
Для общего общения: Llama 3.1 8B — сбалансированная и умная.
-
Для написания кода: DeepSeek-Coder-V2 — понимает сотни языков программирования и отлично помогает с PowerShell-скриптами.
-
Для слабых ПК: Модели с квантованием Q4_K_M — они занимают меньше места почти без потери качества
Шаг 3: Автоматизация рутины (Практический кейс)
Локальный ИИ особенно хорош в связке с системным администрированием. Вы можете скормить ему логи Windows или конфиги, которые по закону нельзя выгружать в онлайн-чат-боты.
Пример запроса к локальной модели:
"Проанализируй список процессов из Event Viewer и напиши скрипт для внесения их в исключения AppLocker, если они подписаны доверенным сертификатом."
Пример взаимодействия с локальным ИИ:
# Скрипт автоматизации исключений AppLocker на основе анализа логов
$LogEvents = Get-WinEvent -LogName "Microsoft-Windows-AppLocker/EXE and DLL" | Where-Object {$_.Id -eq 8003}
foreach ($Event in $LogEvents) {
$FilePath = $Event.Properties[2].Value
$Signature = Get-AuthenticodeSignature -FilePath $FilePath
if ($Signature.Status -eq 'Valid') {
Write-Host "Файл $FilePath имеет валидную подпись. Создаю правило..." -ForegroundColor Green
$Rule = New-AppLockerPolicy -FileInformation (Get-AppLockerFileInformation -Path $FilePath) -RuleType Publisher -User Everyone
# Здесь логика добавления $Rule в вашу текущую политику
} else {
Write-Warning "Файл $FilePath не подписан. Пропуск."
}
}
Сравнение производительности: Сколько «жмёт» ваше железо?
В мире локальных LLM скорость измеряется в токенах в секунду (t/s). Один токен — это примерно 0.75 слова. Для комфортного чтения текста глазами достаточно 10–15 t/s, но для кодинга и анализа больших логов чем выше скорость, тем лучше.
Таблица производительности (апрель 2026)
Данные усреднены для моделей с квантованием 4-bit (Q4_K_M), которое является стандартом для домашнего использования.
| Видеокарта | VRAM | Llama 3.1 (8B) | DeepSeek-Coder (16B) | Mistral Large (123B) |
| RTX 5090 | 32 ГБ | 180+ t/s | 110 t/s | 15 t/s (полностью в VRAM) |
| RTX 5080 | 16 ГБ | 145 t/s | 85 t/s | ~2 t/s (частично в RAM) |
| RTX 4090 | 24 ГБ | 120 t/s | 70 t/s | 8-10 t/s |
| RTX 3060 | 12 ГБ | 45 t/s | 20 t/s | Не потянет |
| Apple M3 Max | 128 ГБ* | 80 t/s | 50 t/s | 12 t/s |
Важное замечание: Если модель не влезает в видеопамять (VRAM), она начинает использовать обычную оперативную память (RAM), и скорость падает в 20–50 раз. Именно поэтому объем VRAM стал важнее «терафлопсов».
Акцент на железо: Конец «эпохи только для игр»
Долгое время топовые видеокарты считались дорогой игрушкой для геймеров. Однако 2025–2026 годы окончательно закрепили за ними статус профессиональных рабочих станций.
Сегодня наличие 16, 24 или даже 32 ГБ видеопамяти — это не про «ультра-текстуры» в 4K. Это про возможность запустить локальный корпоративный «мозг», который:
-
Анализирует гигабайты финансовых отчетов за секунды.
-
Помогает системному администратору писать и отлаживать скрипты без риска утечки коммерческой тайны.
-
Работает как персональный ассистент, доступный 24/7 без подписок и цензуры.
Современные системы (особенно на базе архитектуры Blackwell и последних линеек RTX) превращают домашний системный блок в серверную стойку, которая еще 5 лет назад стоила бы десятки тысяч долларов.
Быстрый старт: Установка (PowerShell)
Порог входа в ИИ сейчас минимален — достаточно одной команды в терминале PowerShell:
# 1. Установка через Winget
winget install ollama
# 2. Запуск первой модели
ollama run llama3.1Визуализация: Как ИИ использует ваше железо
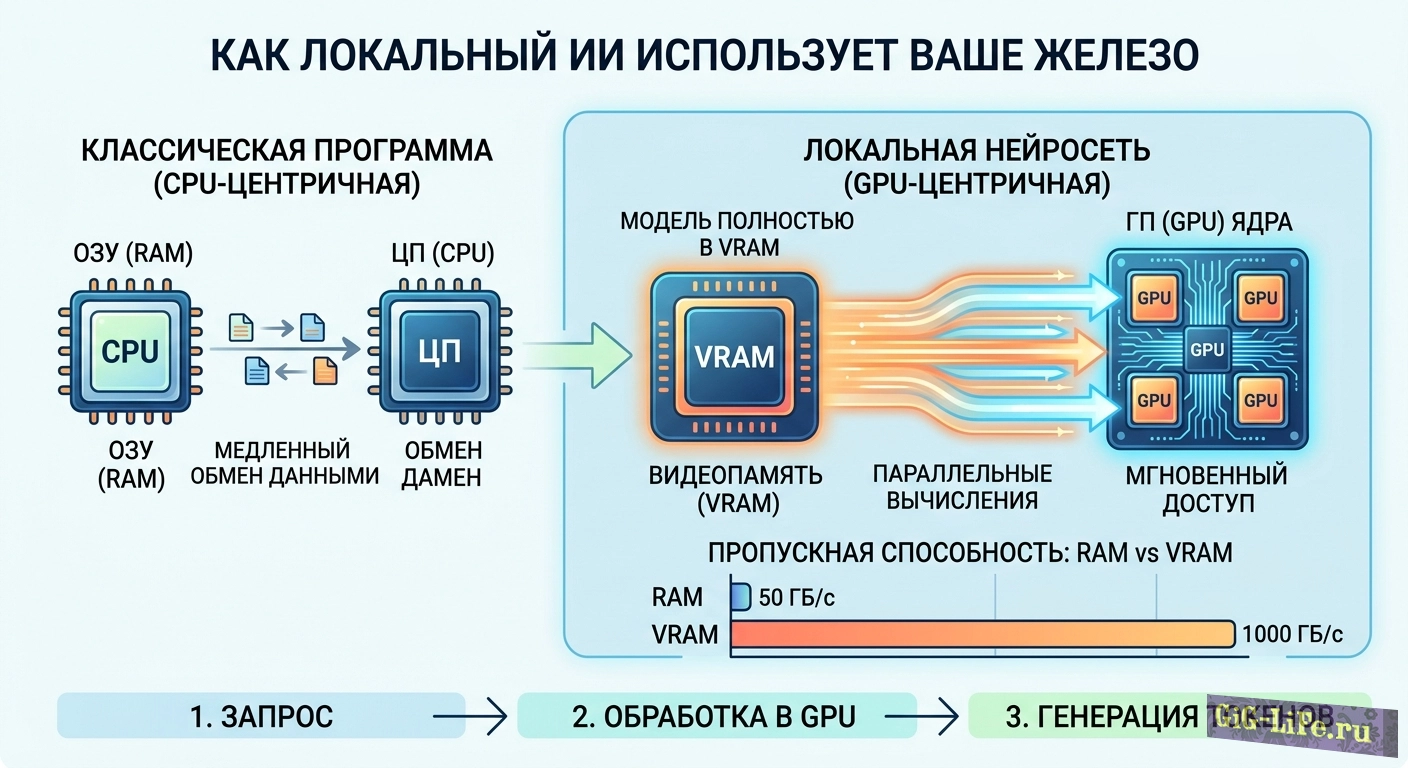
Эта схема иллюстрирует фундаментальное различие в нагрузке на систему:
-
Слева (Красная зона): Классический подход. Обычная программа загружает небольшие порции данных из ОЗУ (RAM) в центральный процессор (CPU). Процессор выполняет вычисления последовательно и возвращает результат. VRAM (видеопамять) здесь практически не задействована, а CPU становится узким местом из-за относительно низкой пропускной способности оперативной памяти.
-
Справа (Зеленая зона): Модель локального ИИ. Вес всей языковой модели (LLM), которые могут занимать десятки гигабайт, полностью загружаются в VRAM. Видеопроцессор (GPU) — это массивно-параллельный вычислитель, который может обрабатывать тысячи задач одновременно. Он получает мгновенный доступ к весам модели через шину памяти с экстремальной пропускной способностью (в 10-20 раз выше, чем у RAM). Это и позволяет генерировать текст мгновенно, а не по одной букве в минуту.
Если вы планируете серьезно использовать локальный ИИ, объем и скорость VRAM на вашей видеокарте — это самый важный параметр.
Комментарии (0)